The Influence of Venue-Specific Historical Data on Odds Formulation in Team and Individual Sports
 Bookmakers incorporate detailed records from individual stadiums, tracks, courts, and courses when they calculate opening odds, and this process draws on performance patterns that span multiple seasons. Teams and athletes show measurable differences in results depending on the location, so operators adjust probabilities to reflect those established tendencies rather than relying solely on overall season averages.
Bookmakers incorporate detailed records from individual stadiums, tracks, courts, and courses when they calculate opening odds, and this process draws on performance patterns that span multiple seasons. Teams and athletes show measurable differences in results depending on the location, so operators adjust probabilities to reflect those established tendencies rather than relying solely on overall season averages.Venue Records Shape Baseline Probabilities
Operators collect data on win rates, scoring margins, and time-specific outcomes at each ground, then feed those figures into proprietary models that generate initial prices. In soccer, clubs that maintain strong home records at high-altitude venues often receive shorter odds when matches occur at those sites, because historical results demonstrate a consistent edge that persists across different squads. Similar adjustments appear in basketball, where teams playing at arenas with distinctive court dimensions or crowd proximity see their implied probabilities shift before tip-off.
Researchers at the Australian Institute of Sport have documented how surface speed and lighting conditions at particular tennis venues alter serve-hold percentages over time, and betting firms apply those same datasets when they set match odds. The result is a set of prices that already embed location-driven variance before any live action begins.
Team Sports Applications
In American football and rugby, operators track yardage and possession metrics tied to specific stadiums that feature unique wind patterns or turf types. These numbers influence point-spread calculations because teams that historically convert red-zone opportunities more efficiently at those locations receive corresponding line movements. During May 2026, several European soccer leagues continue to publish granular venue reports that highlight how fixture congestion interacts with travel distances to certain grounds, allowing odds compilers to refine totals markets accordingly.
Basketball analysts note that teams with strong defensive rebounding percentages at arenas located in colder climates maintain those advantages year after year, prompting modest but consistent shifts in totals odds when games are scheduled at those facilities. The data sets grow with every completed season, so models become more precise as sample sizes increase.
Individual Sports and Location Effects
Golf betting markets rely heavily on course-specific statistics because players exhibit repeatable performance differences on certain layouts. Strokes-gained figures broken down by tee-to-green and putting categories at Augusta National, for example, guide outright and each-way odds well in advance of major tournaments. Horse racing operators maintain detailed records of track biases at individual racecourses, adjusting place probabilities when rail positions or going conditions historically favor front-runners or closers.
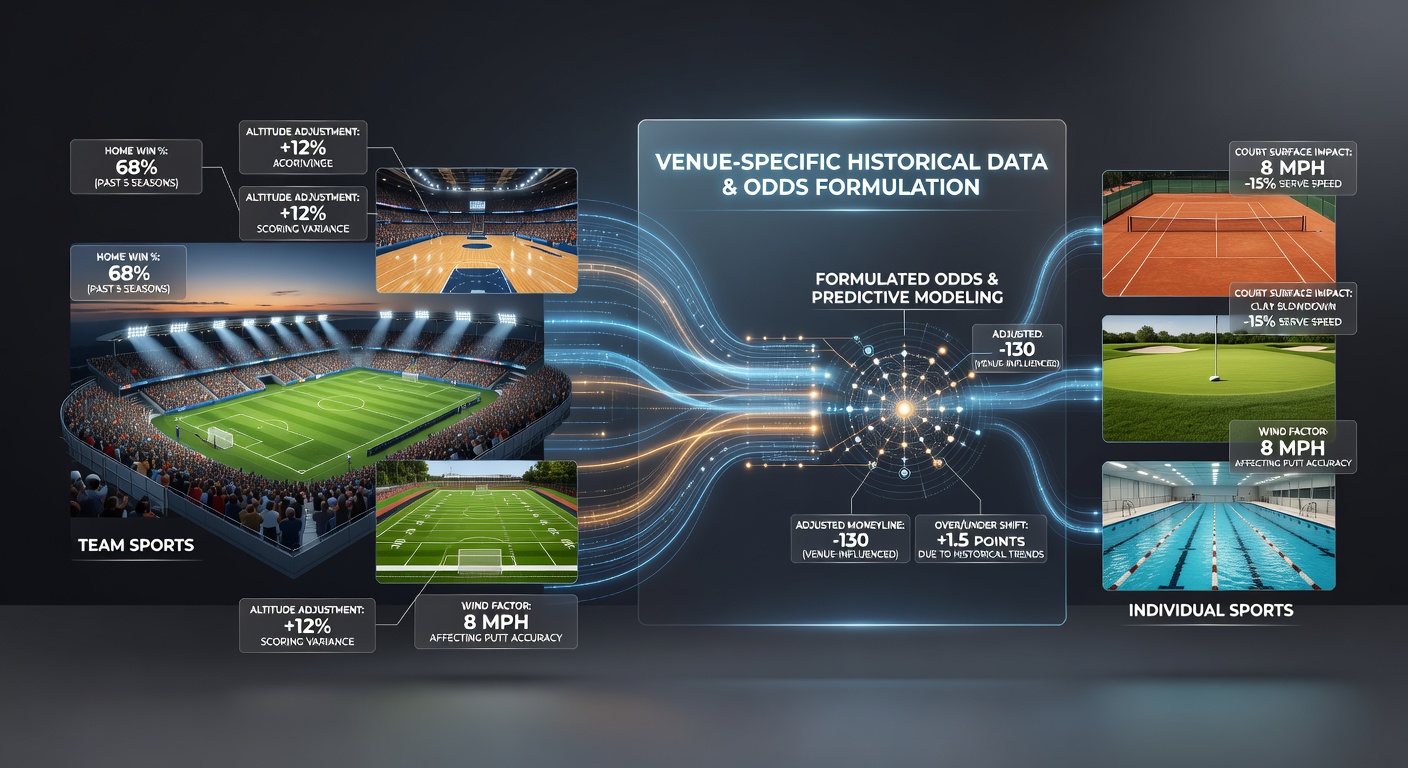
Tennis markets incorporate surface-speed ratings and altitude adjustments for events held at the same stadiums annually. Players who post elevated ace percentages at indoor venues with faster courts see their implied win probabilities rise in the odds when those tournaments return. These adjustments occur because decades of match logs reveal patterns that general rankings alone cannot capture.
Statistical Integration and Model Refinement
Odds compilers combine venue data with regression techniques that weigh recent form against long-term location trends, and they update coefficients whenever new results arrive. This iterative process ensures that prices reflect both established venue quirks and evolving squad compositions. In May 2026, several major sportsbooks reported increased use of machine-learning layers that isolate venue effects from broader seasonal variables, producing tighter margins on niche markets such as first-half totals or set betting.
External research from institutions like the Journal of Sports Sciences supports the value of these layered datasets, showing that location-specific models reduce forecast error compared with generic performance averages. Operators therefore maintain extensive internal databases that catalog every relevant metric by venue rather than aggregating across all locations.
Live Adjustments and Ongoing Data Streams
Once events begin, bookmakers continue to monitor deviations from historical venue norms and adjust in-play odds accordingly. A soccer side that typically dominates set-piece creation at its home ground but falls behind early may see its live prices lengthen because the data indicates such comebacks occur less frequently at that particular stadium. Comparable shifts occur in golf when players fall outside their established scoring ranges on specific holes that have produced consistent birdie or bogey rates over multiple tournaments.
The accumulation of these venue-driven adjustments creates a feedback loop in which each completed match or round adds new observations that refine future probability estimates. This cycle operates across both team and individual sports, ensuring that odds remain tethered to the physical and historical realities of each location rather than abstract season-long trends alone.
Conclusion
Venue-specific historical data functions as a core input for odds formulation because it captures repeatable performance variations that general statistics overlook. Operators across soccer, basketball, tennis, golf, and horse racing integrate these records into their pricing engines, producing probabilities that already account for location effects before markets open. As datasets expand through 2026 and beyond, the precision of these adjustments continues to increase, giving market participants access to prices that reflect the accumulated evidence from each unique sporting environment.